推荐算法全系列
前言
我在本科的毕业论文里写到了基于内容的推荐算法,现在我想把当时写的那点东西拿出来,拆成几个部分,做个推荐算法系列的文章。本文是系列文章的第一篇:基于内容的推荐算法。
本文不懂慎看。你可能会觉得本文含有大量公式有故意装逼的嫌疑,但我不是在瞎写,看懂本文其实只需要高中的数学知识,需要对集合、向量有了解。
基于内容的推荐算法理论基础
基于内容的推荐算法,是建立在物品的内容信息上作出的推荐,和协同过滤算法不同,它的依赖对象并不是用户对物品的评分信息,而是用户的兴趣和物品的内容特征。基于内容的推荐算法一般思路是提取物品的内容特征,并与用户的兴趣做相似度对比,从而找出与用户兴趣最匹配的物品推荐给用户。所以,基于内容的推荐算法有两个关键点需要考虑,一是如何获得物品的内容特征,也就是物品的属性信息,二是如何获得用户的兴趣,并建立合适的兴趣模型。并且,物品的内容特征和用户兴趣必须做合适的量化处理,以便于后面相似度计算的进行。
对于物品内容特征的提取方面,不同类别的物品有不同的提取方式,很难找到一个绝对通用的方法,本课题所要解决的,便是文本内容特征的提取。对于一些直观意义上的物品,例如某件衣服,它的特征往往比较明显,也比较容易获得,例如服装类别、品牌、价格等等。但新闻资讯却并非如此,它的属性特征都是隐性的,它几乎所有的特征都来自于文本之中,不能直观的获得。这就需要借助文本挖掘的相关技术,通过分析文本内容,挖掘出文本的主旨,作为文本的内容特征。文本挖掘的方式有很多种,本课题使用TF-IDF算法,来挖掘资讯内容。
TF-IDF(Term Frequency-Inverse Document Frequency, 词频-逆文件频率)算法,是一种用于资讯勘探的常用加权技术,它用来反映一个词语在某个文本集或语料库上的重要程度。词语的重要性与其出现在文章中的次数成正比,与其出现在语料库或文本集中的次数成反比。TF-IDF算法的公式如下:
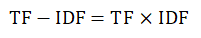
上式中,TF代表词频,即某个词在整篇文章中的出现次数。IDF代表逆向文件频率,逆向文件频率反映了某个词在语料库或文件集上出现的频率。TF的计算公式如下:
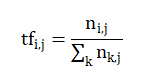
上面公式中,是该词出现的次数,分母则是所有字词出现次数之和。
某一特定词语的IDF值可以下面公式计算得到:
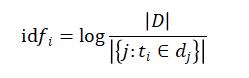
其中,是语料库文件总数。是包含词语的文件数目。
从以上的计算公式中可以看出,TF-IDF算法能挖掘出文本中频繁出现的词,而过滤掉诸如“因为”、“所以”、“的”、“我们”等这类频繁出现的常用词。一片文本,在进行TF-IDF计算后,可以得到“关键词-权重”列表,这些关键词是比较能反映一篇文本的主旨的,适合作为文本的内容特征。
第二个要解决的问题便是用户的兴趣模型。用户兴趣的获取途径有很多,最主要的途径还是用户的历史行为记录,用户在使用资讯推荐系统时,其所产生的阅读、点赞、收藏、评论和搜索等行为均可以反映用户的兴趣偏好。为了更好地反映用户的兴趣特征,可以建立“类别-兴趣-权重”的兴趣列表,由于资讯已经用TF-IDF算法进行了关键词提取,那么用户在阅读资讯时,便将该资讯的关键词和权重加入到对应资讯类别的用户兴趣列表中,这样,用户兴趣列表中较大的值代表用户的比较突出的兴趣,而某一类兴趣权重的总和也可以反映出用户对这类资讯的喜爱程度。这种兴趣模型能够很好的与2.2节的用户兴趣衰减模型结合起来(用户兴趣衰减模型后面系列会讲)。此外,用户的兴趣列表不能无限长,这会使算法性能下降,所以当兴趣列表达到一定数量时,要削减一些权重较小的兴趣。
那么有了内容属性列表和兴趣列表之后,便可以做相似度计算,如果是计算内容与兴趣的相似度,便是为特定用户推荐资讯;如果是计算内容与内容的相似度,便是推荐与某篇资讯相似的资讯;如果是计算兴趣与兴趣的相似度,便是推荐与某个用户有相似兴趣的用户,也就是所谓的“知己”,这在一些带有社交功能的软件产品中是比较实用的。
TF-IDF算法实现
在TF-IDF算法的理论基础上,为了契合本课题的研究方向,可以对算法做出一些微调,从而优化原算法。调整的内容如下:
1):语料库不要存放整篇文本,只需要把文本先进行分词,然后将分词后的一组词语放入语料库,这样做,在进行语料库检索时,只需要逐词比较而不需要和整篇文本进行比较,大大提高效率。
2):不需要对目标文本中所有的词都执行TF-IDF算法,有些常用词可以直接过滤掉。这样做同样能减少计算次数,提高效率
基于3.1节提出的TF-IDF算法理论基础,并结合以上的优化方式,设计TF-IDF算法过程如下:
输入(INPUT):总词数为x的目标文本A,文本A中一组待计算权重值的词语,包含y个文本的语料库B。
输出(OUTPUT):一组“词语-权重”列表。
运算流程:对于每一个待计算权重的词语,都执行下面的操作:(1)统计词语在文本A中出现的次数,记为a。(2)计算a/x的值,其结果记为TF。(3)统计语料库B中出现词语的文本数,记为b。(4)计算的值,记为IDF。(5)计算TF*IDF的值,记为并将和写入到中。至此,完成TF-IDF算法的设计。
基于内容的推荐算法实现
基于内容的推荐算法的实现分为三部分,第一部分为文本内容特征提取,第二部分为用户兴趣模型建立,第三部分为相似文章推荐,下面分别实现这三个部分。
文本内容提取
尽管本文在上节已经详细的介绍了TF-IDF算法的流程,但是想要准确的提取出文章的关键字,仅仅依靠传统的TF-IDF算法是不理想的,仍然需要做一些改进工作。改进工作分为以下几个步骤进行:
(1)文本预处理。考虑到本课题是一个完整的资讯推送系统,并不是单一的算法设计,那么除了测试数据集之外,系统实际运营时的文章来源于用户的发布,用户通过富文本编辑器编辑的文章不仅仅是带有html标签的,甚至会带有一些特殊符号、乱码等内容,这些与文本内容不相关的东西势必会影响分词效果,所以有必要对文本内容进行预处理,过滤掉一些不需要的标签和符号。本课题使用Jsoup做文本内容的清洗,Jsoup是一款基于java的html解析器,它提供的API可以很方便的解析html文本。
(2)改进分词过程。要想通过TF-IDF算法得到一篇文章的关键词,首先要对这篇文章进行分词,即把一篇文章拆分成多个词语,虽然目前有好多中文分词工具能直接使用,但是自然语言是十分复杂而玄妙的,尤其是我们的汉语,仅仅依靠分词工具自带的API来进行分词,其结果是不太理想的,尤其是用在有好多专业术语的文本中,而本课题设计IT类的资讯文本,这类资讯中含有大量的专业术语、专有名词以及缩写简写等等,那么要想实现精准分词,势必要对分词过程进行干预。举个例子,“人工智能”这个词语,如果我们不加任何干预,它会被分成“人工”和“智能”这两个词,这显然是十分糟糕的。再比如,“人工智能”、“ai”、“AI”他们其实是同一个意思,我们应当把它们当成同一个词来处理,但是如果不加干预,分词工具很可能会认为他们是三个不同的词。解决的办法就是在分词的过程中,加入自定义词典,将一些IT领域的专有词收入词典之中,在分词的过程中,与词典进行对照,避免一些比较重要的词被拆开。
(3)基于词语位置作加权优化。TF-IDF算法是建立在词频基础上的,但是这种算法有一个很明显的缺点,就是无法体现出词的位置信息,有时候文章的关键词可能出现的次数并不多,但它往往会出现在一些关键位置上,比如文章的大标题、小标题、文章的开头结尾或者每一段的开头结尾等,因此,各个位置的词都认为重要性相同,这显然是不正确的。解决办法是对重要位置的词语给予较高的权重,可以在统计词频的时候就额外给与频率,但更好的做法是在进行TF-IDF计算之后,对计算结果再进行加权处理。
以上内容,从分词前,分词中,分词后这三个方面入手,对内容提取工作进行了调整优化,实际上,我们不可能将所有的词都看作文章的属性信息,只能选取重要性较高的一些词作为文章的属性信息,因此,可以根据文章的长短来设定关键词的个数,亦可以设定一个阈值,仅选取权重高于阈值的词作为关键词,也可以两者结合,本课题选取第一种方式保留关键词。在对某篇文章进行内容提取之后,他的内容特征可以表示成如下形式:

其中,集合C为该文章的内容特征集合特征集合,元素表示该文章的第i个“关键词-权重”。
至此,文本内容提取部分的工作结束。
用户兴趣模型建立
用户兴趣模型的建立,必须要与内容特征的提取相匹配。在上一节,建立了“关键词-权重”形式的内容特征,那么在用户的兴趣模型中,可以将文本内容的关键词作为用户的兴趣描述,并为其设置权重,用来衡量感兴趣程度。另外,为了提高算法效率,用户兴趣需要按文章类别划分,这样可以提高检索效率。最终建立的用户兴趣模型是“类别-兴趣-权重”的形式。某个用户的兴趣模型可以表示如下:
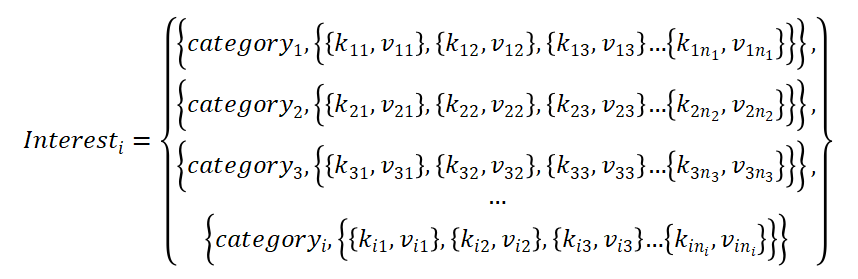
其中,i为类别数量,每个类别的兴趣数量并不固定,第i个类别的兴趣数量为。集合Interest包含了i个类别的兴趣,表示第i个类别,表示类别i中,第个兴趣及其权重。
有了以上用户兴趣模型,在做推荐的时候,只需要和对应类别的兴趣集合进行比较,而无需遍历整个兴趣集合。考虑到兴趣数量不能无限多,可以给每个类别设定最大兴趣数量,当多于最大数量时,删去权重较小的兴趣。
新用户注册时,该兴趣集合为空,之后跟踪用户的浏览行为,每当用户浏览文章时,便将该文章的“关键词-权重”加入到兴趣集合中,如果用户已经存在这个兴趣,便将对应的权重值相加。
至此用户兴趣建模工作结束。
相似文章推荐
在进行了文本内容提取和用户兴趣建模之后,便可以进行最后的推荐工作了。推荐依据的是文章与用户兴趣的相似度,把相似度较高的文章推送给用户,这就涉及到相似度计算方法。相似度计算的方法有很多,考虑到用户兴趣和文本关键字较多,且分布较为稀疏,所以本课题选用余弦相似度方法来计算。设计相似推荐算法过程如下:
输入(INPUT):n个可供推荐的文章集合用户兴趣集合,待推荐文章数量N。
输出(OUTPUT):推荐结果集合RA。
运算流程:对于中的每一个元素,都执行下面的操作:(1)根据文章的类别,在集合中获取对应类别的兴趣集合,记为集合s。(2)构建内容向量,向量中的元素取值对应文章关键词的权重值。(3)构建兴趣向量,向量中每一个元素的取值都参照的关键词和兴趣集合s,如果s中含有和对应关键词匹配的兴趣,那么该元素值为兴趣权重,否则为0。(4)计算。(5)计算,结果即为文章内容与用户兴趣的相似度,将其存入RA中。最后RA中保留相似度最高的前N个元素作为推荐结果输出。
算法实际效果评估
说实话,这个我当时根本就没有去真正评估过,评估的结果数据不准确,有兴趣的可以用准确率和召回率来进行评估。








高谈阔论