线程存在的问题
上下文切换
单核CPU能处理多线程任务,是因为处理器给每个线程分配CPU时间片,线程在CPU时间片内执行任务。
当一个线程的时间片用完,或者因为其他原因挂起,CPU会转而去执行其他线程,这个转换的过程中就涉及上下文切换。
上下文切换的内容:
寄存器的存储内容:CPU寄存器负责存储已经、正在和将要执行的任务
程序计数器存储的指令内容:程序计数器负责存储CPU正在执行的指令位置、即将执行的下一条指令的位置
线程切换的时候需要进入内核态,而内核态(Kernel)的一些数据是共享的,读写时需要同步机制,所以操作一旦陷入内核态就会消耗更多的时间。
也就说,线程的上下文切换会带来一定的开销,线程数越多,上下文切换越频繁,理论上开销就越大,因此,多线程并不一定能带来速度的提升。
内存资源占用
系统在维护线程时需要分配额外的空间,所以线程数的增加还是会提高内存资源的消耗。默认情况下 Linux 系统给每条线程分配的栈空间最大是 6~8MB,这个大小是上限,并不是每条线程真实的栈使用情况。
依赖线程池
线程的使用依赖线程池来统一管理,实际业务代码中不允许使用野线程。
协程的概念
协程,又被称为“轻量级线程”、“微线程”、“纤程(fiber)”等。
协程不是系统级线程,它不像线程一样对应着操作系统中的物理线程。简单来说可以认为协程是线程里不同的函数,这些函数之间可以相互快速切换。
简单来说,协程就是用代码实现的一种多任务异步处理方案,它与操作系统层面是脱节的,因此,协程是用户态的,协程间的切换不需要进入内核态,协程的切换开销要远远小于线程的切换开销。
协程与线程的资源消耗性对比
这里选择java协程框架quasar做对比
maven依赖如下:
<dependency>
<groupId>co.paralleluniverse</groupId>
<artifactId>quasar-core</artifactId>
<version>0.7.10</version>
</dependency> 编写程序,创建10000个协程:
//协程
public static void main(String[] args) throws InterruptedException {
CountDownLatch countDownLatch=new CountDownLatch(10000);
long start = System.currentTimeMillis();
for (int i = 0; i < 10000; i++) {
new Fiber<>(new SuspendableRunnable(){
@Override
public void run() throws SuspendExecution, InterruptedException {
//不能是Thread.sleep();
Fiber.sleep(1000);
countDownLatch.countDown();
}
}).start();
}
countDownLatch.await();
long end = System.currentTimeMillis();
System.out.println("Fiber use:"+(end-start)+" ms");
Thread.sleep(1000000);
System.out.println(1);
} 运行结果:
Fiber use:1480 ms 用时1.48秒,堆内存占用约250MB,总线程数28个
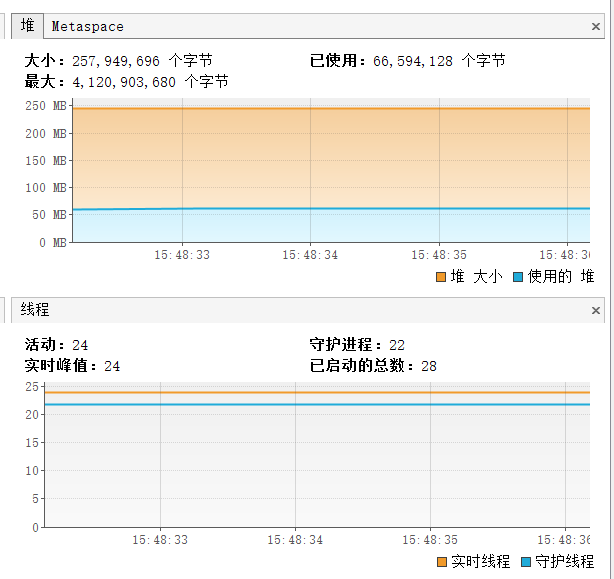
编写程序,创建10000个线程:
//线程
public static void main(String[] args) throws InterruptedException {
//允许一个或者多个线程去等待其他线程完成操作
//CountDownLatch接收一个int型参数,表示要等待的工作线程的个数。
CountDownLatch countDownLatch=new CountDownLatch(10000);
long start = System.currentTimeMillis();
ExecutorService executor= Executors.newCachedThreadPool();
for (int i = 0; i < 10000; i++) {
executor.submit(() -> {
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
//使latch的值减1,如果减到了0,则会唤醒所有等待在这个latch上的线程。
countDownLatch.countDown();
});
}
//使当前线程进入同步队列进行等待,直到latch的值被减到0或者当前线程被中断,当前线程就会被唤醒。
countDownLatch.await();
long end = System.currentTimeMillis();
System.out.println("Thread use:"+(end-start)+" ms");
// Thread.sleep(1000000);
// executor.shutdown();
} 运行结果:
Thread use:3614 ms 总用时3.6秒,堆内存占用1500MB,总线程数10011个
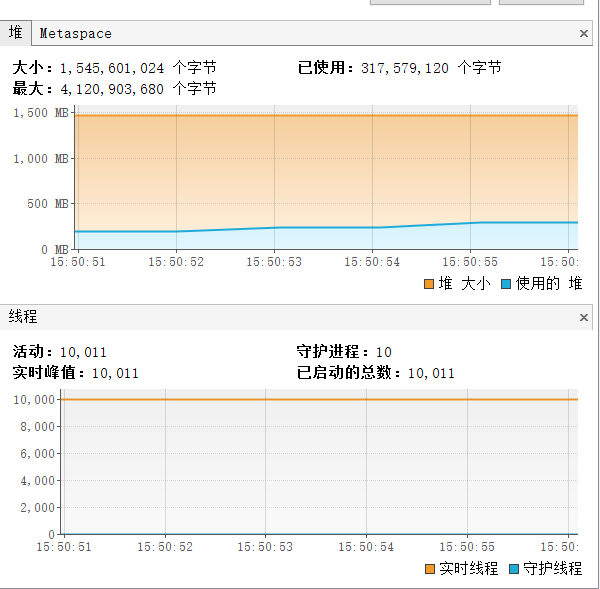
可以看出,协程确实比线程占用的资源少
Go语言的协程调度模型
go从语言层面上支持了并发,GPM模型确实更适合处理并发,这也是go程序员的吹嘘点之一。
先来看一下用go调用一个异步方法有多么简单,只需要在函数前加一个go关键字,该方法就是异步执行的。
package main
func run(arg string) {
// 此线程的任务
}
func main() {
go run("this is new thread")
} GPM协程调度模型
G: 表示goroutine,存储了goroutine的执行stack信息、goroutine状态以及goroutine的任务函数等;另外G对象是可以重用的。
P: 表示逻辑processor,P的数量决定了系统内最大可并行的G的数量(前提:系统的物理cpu核数>=P的数量);P的最大作用还是其拥有的各种G对象队列、链表、一些cache和状态。
M: M代表着真正的执行计算资源,也就是线程。在绑定有效的p后,进入schedule循环;而schedule循环的机制大致是从各种队列、p的本地队列中获取G,切换到G的执行栈上并执行G的函数,调用goexit做清理工作并回到m,如此反复。M并不保留G状态,这是G可以跨M调度的基础。
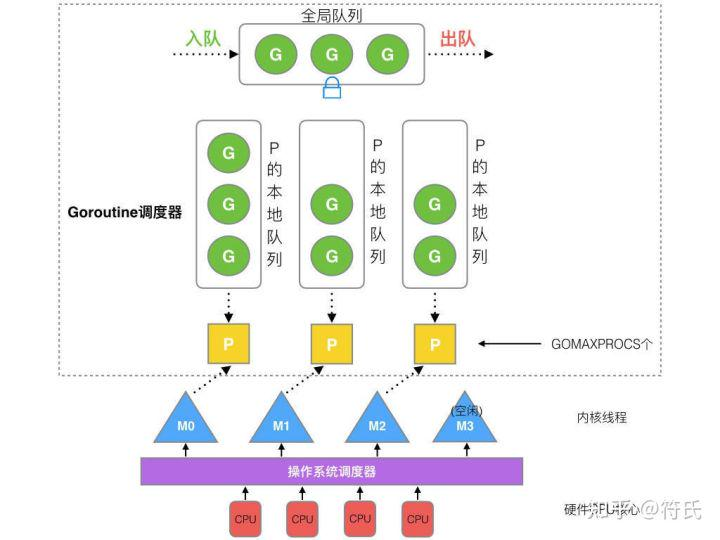
程序启动时,先初始化和核数一样的P。
当创建一个goroutine时,优先尝试放在本地队列,如果本地队列满了,则会把本地队列的前半部分和这个新的goroutine一起移到全局队列中。
如果没有可用的P的时候,新goroutine加入全局队列中。
如果获取到空闲的P,那么尝试去唤醒一个M,没有可用的M的时候新建一个M。
当M关联上P时,且local队列有任务时,可以一直从p的local队列中取goroutine执行。
当P的local队列中没有goroutine时,则会尝试从全局队列中拿一部分放在本地队列中,这个过程是加锁的。
当从全局队列没取到时,会尝试从其他的P的local队列偷取一半放在自己的本地队列中
当一个G发生系统调用的时候,P会断开与当前的M的关系,尝试从M的空闲队列中获取一个M来继续执行剩下的goroutine。
当上面的G系统调用结束后,M尝试获取一个P来继续执行,如果没获取到,则会把这个g放到全局队列中,并且自己进入M的空闲队列。这里不是销毁M,避免后面又要创建M,造成不必要的开销。
什么是系统调用?
操作系统提供给程序员的接口就是系统调用,系统调用是用户程序和硬件设备之间的桥梁,系统调用会进入内核态。
六大类系统调用
进程控制(process control)
文件管理(file manipulation)
设备管理(device manipulation)
信息维护(information maintenance)
通信(communication)
保护(protection)
事件循环(Event Loop)
这又是一种新的实现异步编程的方式
Event Loop:所有同步任务在主线程上执行,形成一个执行栈---->主线程之外还有任务队列,当异步任务执行有结果的时候就会在任务队列放置一个事件------>当执行栈中的同步任务执行完毕,就会读取任务队列中的事件,将其对应的异步任务放入执行栈执行,这个不断循环往复的过程,就称为事件循环,也就是Event Loop
见下文node.js
对比不同语言的异步编程方式
Java
上文提到过的协程库Quasar,看一下某篇博客里做的性能测试

为什么java几乎不提协程?
这里有必要说明一下,协程要想完全发挥威力,需要一个前提条件,那就是你的代码必须是无阻塞的,这点很好理解,因为一旦协程方法里出现阻塞操作,那么当前线程也会被阻塞。然而我们知道,整个java生态中,阻塞的库太多。如果考虑能把java中的I/O操作都封装成非阻塞的(例如Netty),那么Quasar还是有用武之地的。
列出几个java和异步编程相关的项目:
Vert.x3 java版的Node.js
dragonwell8 阿里OpenJDK,JVM层面实现的协程
java中的CompletableFuture ,有回调地狱问题
京东异步编排框架asyncTool
Node.js
node在异步编程这块,可以简单用三个词来概括:单线程、非阻塞I/O、事件驱动
这里的单线程其实指的是主线程
前两个好理解。
事件驱动,可以这样来简单描述:
1、有几个事件队列
2、当有新事件发生时,加入到对应事件队列中
3、有个大循环,不断的从事件队列中取出事件并执行,循环往复。
复杂点描述是这样的:
┌───────────────────────┐
┌─>│ timers │
│ └──────────┬────────────┘
│ ┌──────────┴────────────┐
│ │ I/O callbacks │
│ └──────────┬────────────┘
│ ┌──────────┴────────────┐
│ │ idle, prepare │
│ └──────────┬────────────┘ ┌───────────────┐
│ ┌──────────┴────────────┐ │ incoming: │
│ │ poll │<─────┤ connections, │
│ └──────────┬────────────┘ │ data, etc. │
│ ┌──────────┴────────────┐ └───────────────┘
│ │ check │
│ └──────────┬────────────┘
│ ┌──────────┴────────────┐
└──┤ close callbacks │
└───────────────────────┘
//注意:途中每个方框被称为事件循环的一个阶段,这六个阶段为一轮事件循环 Event loop
timer阶段(定时器):执行setTimeout(callback)和setInterval(callback)
I/O callbacks阶段(I/O回调):执行某些系统操作的回调(例如TCP错误类型)
idle、prepare阶段(空转):仅node内部使用
poll阶段(轮询):获取新的I/O事件,例如操作读取文件
check阶段(检查):执行 setImmediate() 设定的callbacks;
close callbacks阶段(关闭回调):比如 socket.on(‘close’, callback) 的callback会在这个阶段执行;
当有异步任务产生时,会交给C++维护libuv的线程来处理,异步任务的回调函数会被注册进对应的事件队列,node主线程会不断的从这些事件队列中取出事件来执行。
因此,在代码层面上,node的异步场景与回调函数是分不开的。但是,当业务逻辑复杂时,回调里面套回调,嵌套了无数层,导致代码成了这个样子:
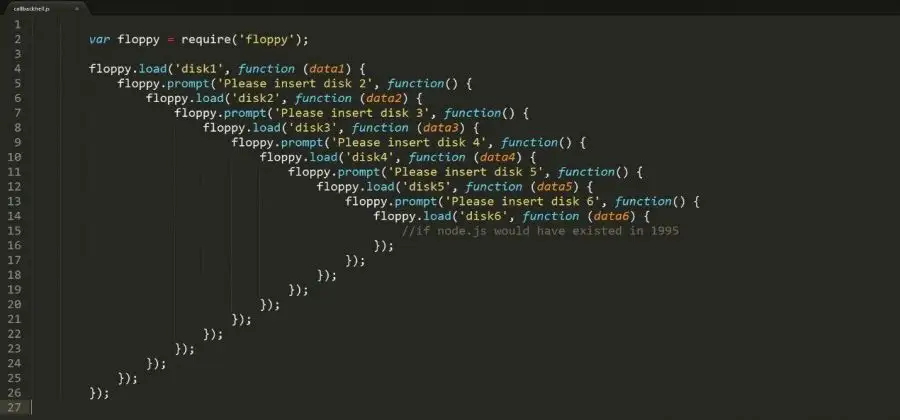
这就是回调地狱。
node怎么解决回调地狱问题?https://juejin.cn/post/7110513834875420680
C#
C#和java很像,原生支持多线程
Python
不了解
C/C++
这个就不讨论了,什么都可以实现的底层语言
PHP(世界上最好的语言)
PHP原生并不支持多线程
传统的 php-fpm是一个进程执行一次请求,有多少并发,就要有多少进程,不愧是世界上最好的编程语言!但这显然是不能接受的,因此PHP有很多异步编程的框架,要么是实现了事件循环的框架,要么是协程调度框架(基于yield生成器)。
和事件循环有关的框架有:Swoole 和 WorkerMan
和协程有关的框架:ampphp 和 swoole
参考文档
- https://zhuanlan.zhihu.com/p/446993465
- https://www.cnblogs.com/carySir/p/12530133.html
- https://baijiahao.baidu.com/s?id=1702448043936293527&wfr=spider&for=pc
- https://blog.csdn.net/weixin_44211968/article/details/120035592
- https://zhuanlan.zhihu.com/p/469899375
- https://blog.csdn.net/Dimuzero/article/details/121795963








高谈阔论